前言
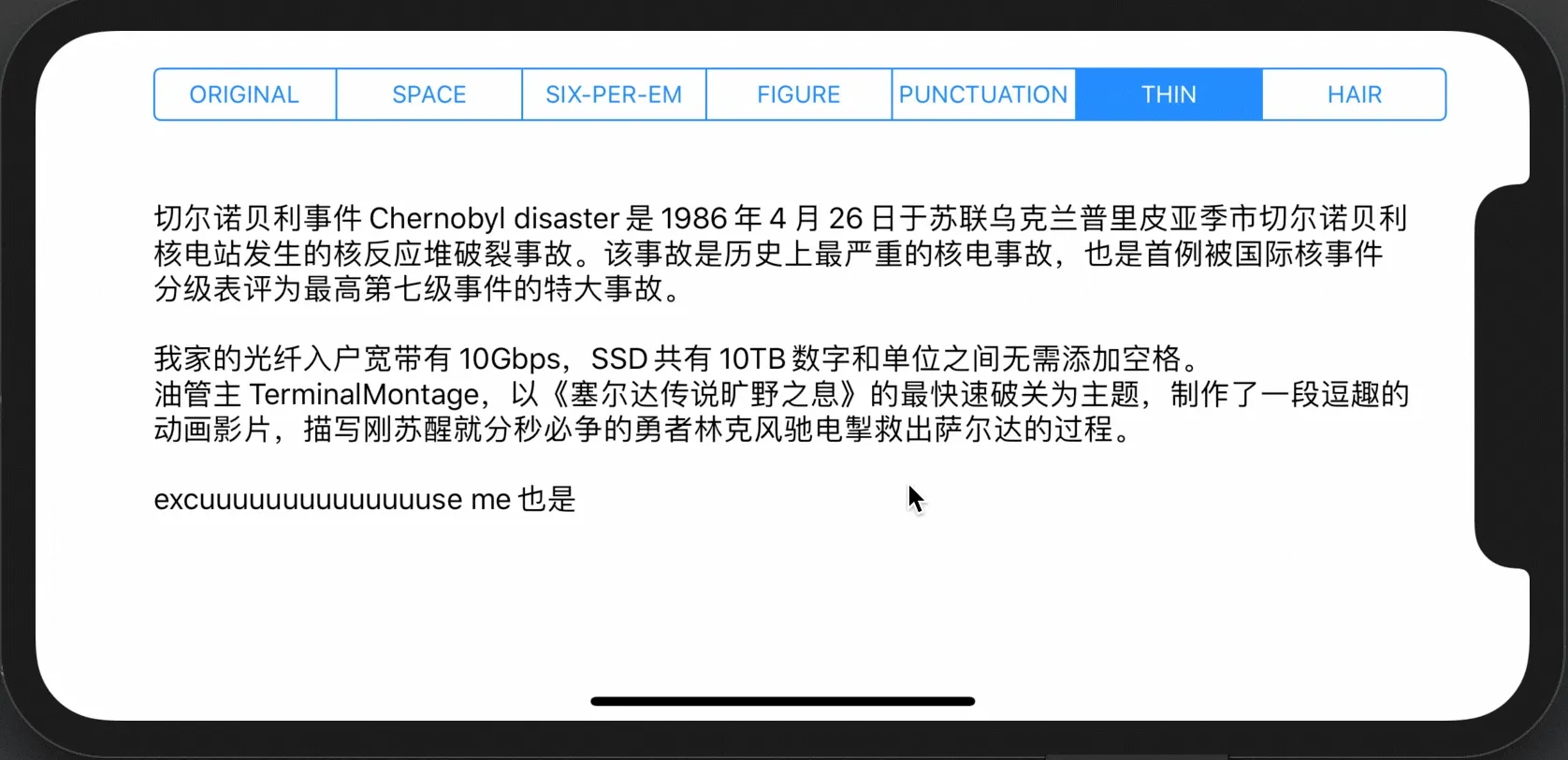
在平时的文字输入时,我总会在中文和英文,中文和数字中间添加一个普通空格 (U+0020)。在文本布局时不会显得那么拥挤,也一定程度上提升了阅读体验。前一段时间即刻 App 添加了一个中西文之前默认添加一个特殊空格的特性,体验之后发现,这样的宽度短于普通空格的特殊空格,即不会出现没有空格时过于拥挤的布局,也不会出现普通空格间距过大的问题。查阅了一些资料后,找到一篇关于 Sapce 的 Unicode 表,想不到空格还有这么多的种类。
之前的开发工作中,出现过一些,长文本在 iOS 设备中不换行的 Bug,这个问题曾经困扰了我许久,后来无意中发现了一个叫 NO-BREAK SPACE 的空格,其 Unicode 为 U+00A0。在 App 中的表现就是,设置了 UILabel 的 numberOfLines 属性为 0 同时 breakMode 设置为 byWords,含有该空格的文本也不会换行,即使限制了 UILabel 的宽度,换行时仍然会拆开单词换行。
鉴于即刻 App 这个新需求带来的完美效果,着手简单实现一下。不过不知道即刻选用的空格种类,这里经过多次比较之后,我使用了 U+2009,被称为 THIN SPACE 的空格。
实现
这个需求,我的第一反应就是使用正则来匹配给定字符串的如下情况
- 中文 + 英文
- 英文 + 中文
- 中文 + 数字
- 数字 + 中文
- 中文 + 符号
- 符号 + 中文
- 忽略英文和数字的组合,即计量单位,如 10TB
想到用 Swift 来实现正则表达式,就会有点头皮发麻。先不说 NSRegularExpression 的部分 API 中还带有 NSRange。就是正则表达式里面,还需要添加 / 转义符,就是一个噩梦,可读性大大降低。不过,好在 Swift 5 新增的 Raw String 可以完美解决这个问题。用到的所有正则表达式如下
let chinese = #"[\u2E80-\u2FFF\u31C0-\u31EF\u3300-\u4DBF\u4E00-\u9FFF\uF900-\uFAFF\uFE30-\uFE4F]"# // 匹配中文
// 使用 tuple
// base 基础符号。单一符号,不成对
// open 与 close 成对出现的符号
let punc = (
base: #"[@&=_\,\.\?\!\$\%\^\*\-\+\/]"#,
open: #"[\(\[\{\'"<‘“]"#,
close: #"[\)\]\}\'">’”]"#
)
// 拉丁字符。数字、字母等
let latin = #"[A-Za-z0-9\u00C0-\u00FF\u0100-\u017F\u0180-\u024F\u1E00-\u1EFF]|\#(punc.base)"#
由于需要匹配的情况有前后之分,下面用一个数组,将上述的正则表达式组合成两个完整的正则表达式。通过 compactMap 获取到最后的 NSRegularExpression 实例数组。
let patterns = [
#"(\#(chinese))(\#(latin)|\#(punc.open))"#,
#"(\#(latin)|\#(punc.close))(\#(chinese))"#
].compactMap { try? NSRegularExpression(pattern: $0) }
最后,就可以通过 stringByReplacingMatches(in:options:range:withTemplate:) 方法,通过 template 替换原有的字符串了。
let unicode = "\u{2009}"
patterns.forEach { (regex) in
result = regex.stringByReplacingMatches(in: result, options: [], range: NSMakeRange(0, result.count), withTemplate: "$1\(unicode)$2")
}
return result
下面的 Gif 比较了不添加空格、添加普通空格和 U+2009 空格的区别。